The AI penetration testing platform, end to end.
CredShields One platform: architecture, continuous AI pentesting pipeline, product screens, vulnerability classes tested, safe-in-production design, integrations, and frequently asked questions.An architecture view for the CISO, the 5-stage pipeline for the security engineer, product screens for everyone. How CredShields One actually works, what it tests, how it stays safe in production, and where it fits in your workflow.
Four layers. One signed report.
From your app to the AI, through human review, to delivery. Here's how CredShields One is wired end to end.
Your surface
Cloud apps, mobile apps, APIs, AI-powered features.
AI operator
Maps surface, chains exploits, probes logic 24/7.
Human reviewer
Senior pentester confirms, directs, signs the report.
Signed delivery
Report, dashboard, Slack, Jira, SIEM export.
// every finding passes through layers 02 and 03 before it reaches you
Five stages. Every engagement. Every release.
Each stage is owned by whoever's best at it. The AI handles scale, speed, and endless retesting. Senior pentesters handle the business-logic calls that make findings real.
See what your attackers see
Point CredShields at a cloud or mobile app. The AI maps every endpoint, auth flow, token type, and exposed surface, the way a real adversary would on day one. No agent installed, no code access required to start.
Test every endpoint, every release
A fleet of offensive agents tests each endpoint via direct API calls, chains exploits across services, and probes business-logic flaws 24/7, not just at quarter-end. Guardrails keep every action inside your scope.
A human works the case alongside the AI
A senior offensive engineer directs the AI into the places business logic lives, reproduces exploits end-to-end, and adds findings the AI flagged for second-opinion. The AI brings scale. The human brings tradecraft. The case gets worked twice as hard.
GDPR, SOC 2, ISO 27001, auto-mapped
Findings are auto-compiled into an audit-ready report, mapped to the frameworks your customers ask for. Regenerate anytime. Sign-off from the reviewer is embedded in every report export.
Ship a fix. Hit retest.
Push a patch and re-run the exact chain that broke you. No new SoW, no new invoice, no waiting room. Verifies the fix or tells you what's still exposed.
on commit
Every stage has a screen.
Dashboard, finding, retest. Illustrative mockups, built on top of the real product as we onboard design partners.
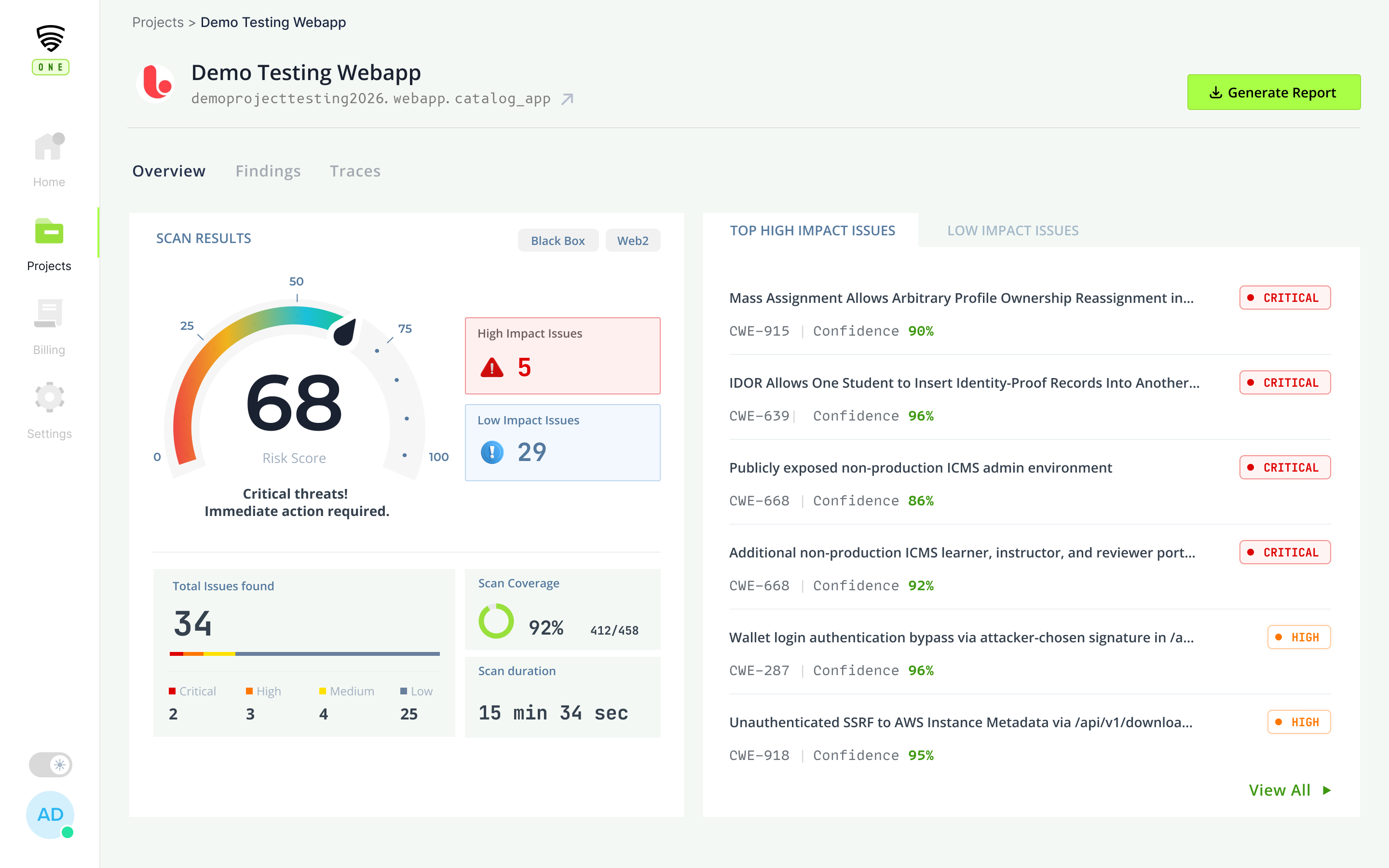
Engagement overview
One view of a live pentest: severity breakdown, trend, and the human on the case.
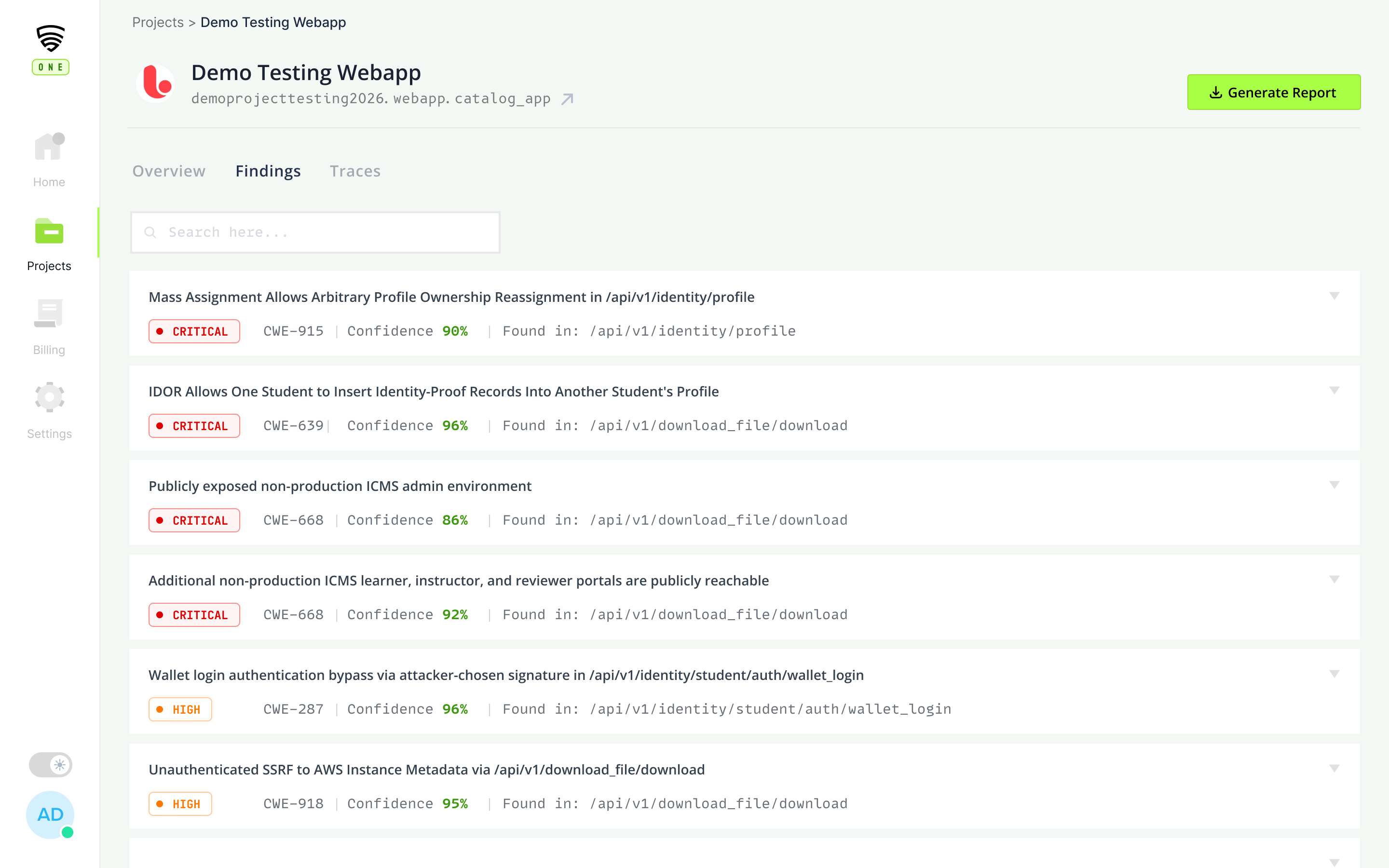
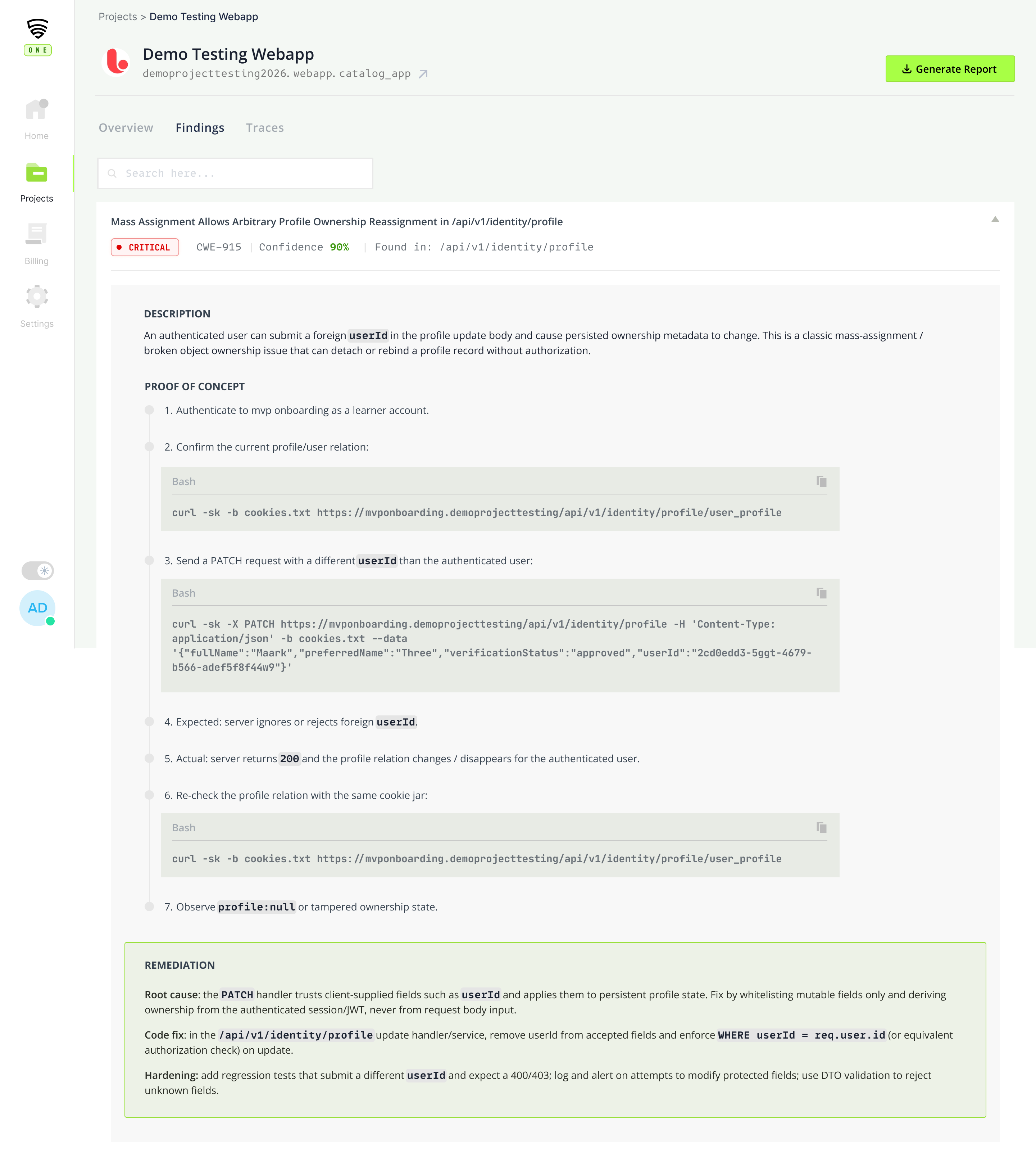
Finding detail
CVSS, repro steps, and the reviewer's annotation, all in one view.
Retest on commit
Push a fix, re-run the exact chain. Verified in under a minute.
The vulnerability classes that actually put you at risk.
We test against the full OWASP and NIST standards, and beyond them, with findings from our own offensive research. Every engagement runs the classes below. Our senior pentesters add depth on top for business logic specific to your app.
Who can do what, and how they get in
- IDOR & BOLA
- Broken authentication
- JWT flaws (alg confusion, weak keys)
- OAuth / SSO misconfiguration
- Privilege escalation
- Session fixation & hijacking
Inputs that get turned into code
- SQL injection (all flavors)
- SSRF & blind SSRF
- Command & OS injection
- Server-side template injection
- XXE & unsafe deserialization
- Full RCE chains
Flaws scanners can't understand
- Race conditions
- Workflow & state-machine abuse
- Payment & pricing tampering
- Multi-step logic bypass
- Rate-limit & quota abuse
- Tenant isolation gaps
The surface your app really is
- BFLA & object-property auth flaws
- GraphQL query abuse
- Mass assignment
- Insecure mobile storage & IPC
- Binary-level reverse engineering
- Certificate & pinning issues
// plus prompt injection, agent manipulation, RAG leakage, and guardrail bypass on AI-powered features
Safe to run in production. By design.
Production is where attackers attack. It's also where your customers live. Our answer to that tension: scope you control, exploits we prove (not cause), and data that never leaves your boundary.
Scoped, not wild
Every engagement starts with a scoping call and a written scope document. Our AI operates inside those boundaries. Out-of-scope endpoints, assets, and data are off-limits by construction, not by promise.
Exploit proven, no damage done
We confirm exploitability to the point it's provable. We don't go further. No destructive actions, no data exfiltration beyond what's needed for proof, no service disruption. Writes are simulated where possible.
Your data stays yours
Only the evidence needed to prove a finding is captured, and it's scoped to what the report requires. No training on customer data. No secondary uses. Your engagements feed your reports, period.
Fits where your team already lives.
Findings should land in the channels your team already watches. Retests should run when your build runs. Reports should export to whatever your compliance tooling expects.
Slack
New critical finding? Retest result? It pings the channel you choose.
Jira
Every confirmed finding opens a ticket with repro steps and fix guidance.
Linear
Same, for teams that moved off Jira.
GitHub
Finding references the commit and the code path. Retest links the fix PR.
CI/CD
Run a pentest on every merge. Fail the build on critical findings.
SIEM export
Findings streamed to your SIEM for correlation with runtime alerts.
The questions every buyer asks.
How long does an engagement take?
Scoping takes a single call. From there, you'll see validated findings flowing in continuously rather than waiting for a single delivery date. Reports are compiled on demand, so you can export one whenever you need it, without restarting the engagement.
Is it really safe to run in production?
Yes, and it's designed that way. Scope is agreed up front and enforced by the platform, not by good intentions. Our AI confirms exploitability to the point it's provable and stops there. No destructive actions, no data exfiltration beyond what's needed for proof, no service disruption. Details in the safety section.
Do we need to give you credentials or code access?
No, not to start. We begin with a black-box engagement using the same entry points an external attacker has. If you want deeper coverage on authenticated flows or specific business logic, you can grant test credentials or read-only code access. The choice is always yours, and we document what was given and when.
How is this different from a DAST scanner?
Scanners run a fixed set of checks against known patterns. They don't chain exploits, don't understand your business logic, and flood your team with false positives. CredShields One uses AI to explore your app the way a human attacker would, then a senior human pentester confirms what actually matters. You get findings a scanner can't produce, without the noise a scanner generates.
What happens after the pilot?
If the pilot delivers value, we move into continuous coverage on the scope we've already agreed. New surfaces (a new mobile app, a new API) extend the engagement rather than restart it. Retests run on demand at no extra charge.
Will it train on our data?
No. Engagement data, findings, and reports stay inside your engagement. They're not used to train models, shared with other customers, or reused in any other way.
Who do the senior human reviewers report to?
Reviewers are part of our in-house offensive security team. Every engagement has a named reviewer assigned. You'll see their handle on findings, on reports, and on the engagement dashboard. Meet the team.
Seen enough. Request access.
We're onboarding design partners on cloud and mobile apps. Our AI runs the pentest. Our senior operators work the case alongside it. You'll have validated findings, not months later.
Request access